Joins
Claro que você já ouviu falar dos tipos de joins
Quero destacar os pontos principais entre os joins existentes e dar exemplos de seus usos
A ideia é abordar vários tópicos sobre SQL e joins é um deles, muito importante para sua vida diária usando SQL
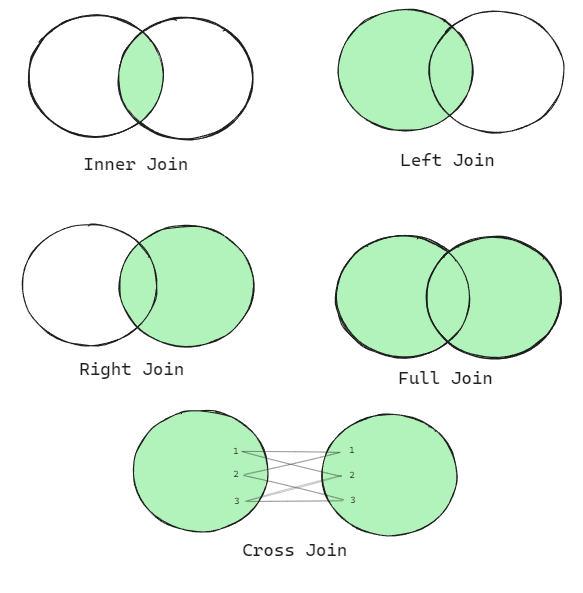
- *Usaremos o banco de dados que criamos no artigo de modelagem de dados.
INNER JOIN
Recupera registros de ambas as tabelas onde há uma correspondência com base na condição especificada. Se não houver registro correspondente em qualquer uma das tabelas, as linhas não aparecerão no conjunto de resultados.
Um INNER JOIN é o tipo mais comum de join em SQL, tenho certeza de que você já fez pelo menos uma vez.
Ele combina linhas de duas tabelas com base em uma coluna relacionada entre elas, você precisa de um campo que exista em ambas as tabelas.
O conjunto de resultados contém apenas as linhas para as quais a condição de junção é verdadeira em ambas as tabelas, se o id for órfão, provavelmente há algo errado com suas tabelas.
Para INNER JOIN você pode escrever apenas JOIN.
Exemplo:
1
2
3
4
5
6
7
8
SELECT
h.[name],
h.[description],
t.[date],
t.[level]
FROM tracking t
INNER JOIN habits h ON (t.[habit_id] = h.[id])
-- JOIN habits h ON (t.[habit_id] = h.[id])
Resultado:
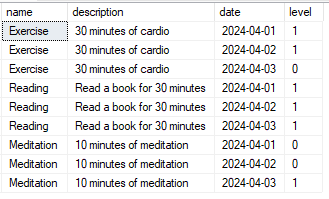
Nesse exemplo estou realizando o join para identificar o nome e a descrição de cada hábito praticado nas datas.
LEFT JOIN
LEFT JOIN é útil quando você deseja recuperar todos os registros da tabela esquerda, independentemente de existir ou não um registro correspondente na tabela da direita.
Se não houver correspondência na tabela da direita, valores NULL são retornados para as colunas da tabela da direita.
Exemplo:
1
2
3
4
SELECT
*
FROM habits h
LEFT JOIN contacts c ON (h.[contact_id] = c.[id])
Resultado:

Podemos verificar que o contato de id 03 não existe na tabela de contacts, sendo assim, o retorno relacionado a essa linha será NULL.
RIGHT JOIN
É semelhante a um LEFT JOIN, mas recupera todos os registros da tabela direita e os registros correspondentes da tabela esquerda.
Se não houver correspondência na tabela esquerda, valores NULL são retornados para as colunas da tabela esquerda.
RIGHT JOIN é menos comumente usado do que LEFT JOIN, mas pode ser útil em determinadas situações, especialmente quando você deseja se concentrar nos dados da tabela direita.
Exemplo:
1
2
3
4
SELECT
*
FROM habits h
RIGHT JOIN contacts c ON (h.[contact_id] = c.[id])
Resultado:

Podemos verificar que o contato de id 04 não existe na tabela de contacts, só que ele não está relacionado a nenhum hábito, por isso, os retornos da tabela habits voltam como NULL.
FULL JOIN
Recupera todos os registros quando há uma correspondência na tabela esquerda ou direita.
Se não houver correspondência, valores NULL são retornados para as colunas da tabela sem uma linha correspondente.
FULL JOIN é útil quando você deseja recuperar todos os registros de ambas as tabelas e ver onde eles correspondem ou não.
Exemplo:
1
2
3
4
SELECT
*
FROM tracking tr
FULL JOIN time t ON (tr.[date] = t.[date])
Resultado:
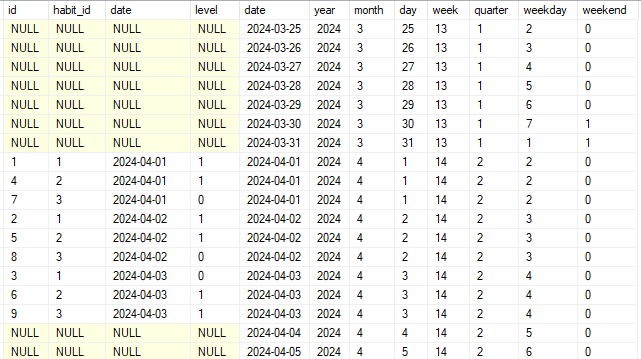
Aqui estou criando uma linha do tempo nesses dados, consigo analisar todos os dias que um hábito foi realizado e os dias que não.
Nesse exemplo ele vai duplicar apenas a linha em que ocorreu um hábito, se três hábitos foram realizados no dia 02 então vão existir três linhas no dia 02. Isso é um FULL JOIN, você vai identificar as ocorrências em ambas as tabelas.
Exemplo completo:
1
2
3
4
5
6
7
8
9
SELECT
h.[name],
h.[description],
t.[date],
tr.[date],
tr.[level]
FROM [tracking] tr
FULL JOIN [time] t ON (tr.[date] = t.[date])
LEFT JOIN [habits] h ON (h.[id] = tr.[habit_id])
Resultado:
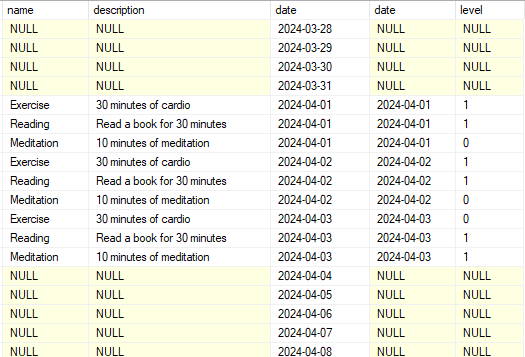
Foi realizado um LEFT JOIN para buscar os campos da dimensão e ter uma query mais completa, ligando duas dimensões em uma fato. Estamos analisando as informações de um timeline com as descrições da outra tabela de dimensão.
Já consegue tirar alguns insights?
CROSS JOIN
Retorna o produto cartesiano das duas tabelas, combinando cada linha da primeira tabela com cada linha da segunda tabela.
Ao contrário de outros joins, não requer nenhuma condição a ser atendida.
CROSS JOIN gera um conjunto de resultados com o número total de linhas igual ao número de linhas em cada tabela.
Pode ser útil para gerar combinações de dados, mas também pode resultar em grandes conjuntos de resultados.
Exemplo:
1
2
3
4
SELECT
*
FROM habits hr
CROSS JOIN contacts
Resultado:
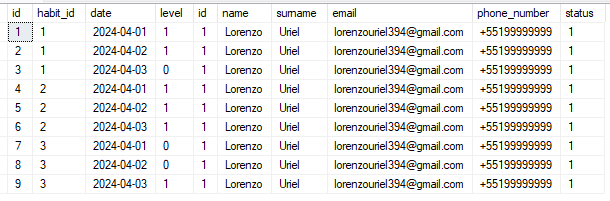
Vou trazer um exemplo parecido com o utilizado no FULL JOIN e vamos identificar as suas diferenças.
Exemplo completo:
1
2
3
4
5
6
7
8
9
SELECT
h.[name],
h.[description],
t.[date],
tr.[date],
tr.[level]
FROM [habits] h
CROSS JOIN [time] t
LEFT JOIN [tracking] tr ON (h.[id] = tr.[habit_id] and t.[date] = tr.[date])
Resultado:
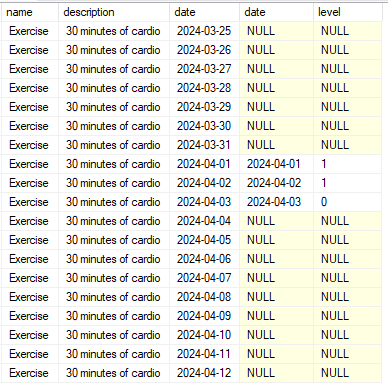
A diferença do CROSS e do FULL é que com o FULL duplicamos apenas as linhas que existem ocorrências, já o CROSS vai cruzar todas as linhas da tabela time com a tabela habits.
Ou seja, se existem 366 registros na tabela time e apenas 03 registros na tabela habits, o SQL vai retornar 1.098 registro. No caso do LEFT JOIN utilizamos com o mesmo objetivo de identificar em qual data aquele hábito foi realizado.
Qual usar mais?
De fato, INNER JOIN é o mais utilizado em consultas SQL.
Pessoalmente, tendo a recorrer aos JOINs LEFT e RIGHT quando estou analisando as tabelas que possuo, muitas vezes para examinar a presença ou ausência de valores. Ou como mostrado nos exemplos acima, as vezes precisamos de um LEFT para buscar apenas os registros existentes, sem duplicar.
FULL JOIN, por outro lado, é reservado para cenários como o descrito acima – instâncias em que precisamos correlacionar com uma timeline. Você também pode usar ao analisar dados onde alguns registros podem estar ausente em um conjunto de dados, mas presente em outro, para garantir que nenhum dado seja perdido durante a operação de junção.
CROSS JOIN é útil quando você precisa gerar todas as combinações possíveis de dados, como ao criar dados de teste para um banco de dados ou ao realizar certos tipos de análise. Você também pode usar em cenários onde você precisa comparar cada item de um conjunto com cada item de outro conjunto.
Vai muito da necessidade e do seu desafio!
UNION vs. UNION ALL
Tanto UNION quanto UNION ALL são usados para combinar resultados de duas ou mais consultas em uma única lista de resultados. No entanto, eles têm diferenças importantes em seu comportamento:
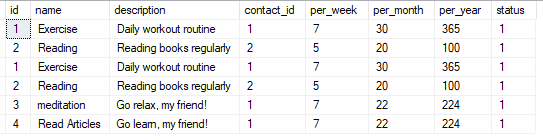
- Obs: Criei uma tabela idêntica a minha
habitse adicionei novos registros para fins de comparação.
UNION
Combina os resultados de duas ou mais consultas em uma única lista de resultados.
Ele remove automaticamente qualquer registro duplicado que possa surgir entre as consultas.
É útil quando você deseja combinar resultados de várias consultas e garantir que não haja registros duplicados nos resultados finais.
A ideia é gerar um conjunto de resultados único.
Exemplo de UNION:
1
2
3
4
5
6
7
8
9
SELECT
*
FROM [tracking_habits].[dbo].[habits]
UNION
SELECT
*
FROM [tracking_habits].[dbo].[old_habits]
Resultado:

UNION ALL
Combina os resultados de duas ou mais consultas em uma única lista de resultados.
No entanto, ao contrário do UNION, ele não remove registros duplicados - simplesmente combina todos os resultados, incluindo duplicados, se houver.
É mais rápido que o UNION, pois não precisa verificar e eliminar registros duplicados.
Use UNION ALL quando você deseja combinar todos os resultados ou quando tem certeza de que não haverá registros duplicados e deseja melhorar o desempenho.
Exemplo de UNION ALL:
1
2
3
4
5
6
7
8
9
SELECT
*
FROM [tracking_habits].[dbo].[habits]
UNION ALL
SELECT
*
FROM [tracking_habits].[dbo].[old_habits]
Resultado:
Quais são os próximos passos?
Salve o conteúdo, crie um exemplo de banco de dados e comece a praticar. É a melhor maneira de aprender!
Se tiver alguma dúvida, entre em contato.
Obrigado por ler até aqui!