Padrões de Banco de Dados
Você provavelmente já usou e está familiarizado com alguns dos padrões que apresentarei hoje. É provável que você utilize a maioria deles para ajudar a resolver problemas em sua função.
Mas se você nunca os usou, espero que este artigo possa dar o primeiro passo para aplicar boas práticas aos seus bancos de dados.
Explorarei esses padrões fundamentais de banco de dados, que podem ajudá-lo a resolver problemas comuns, como melhorar a velocidade de consultas, gerenciar grandes conjuntos de dados, garantir disponibilidade dos dados e manter a consistência.
Aqui estão os tópicos que abordaremos:
- Indexing
- Partitioning
- Replication
- Sharding
- Consistent Hashing
- ACID
- CAP Theorem
Indexing
Vamos começar com o que todos queremos ao gerenciar bancos de dados: consultas rápidas!
Indexing é uma técnica usada em bancos de dados para acelerar a recuperação de dados de forma mais eficiente. O melhor exemplo é o índice de um livro: com ele, você pode localizar rapidamente a informação, indo diretamente ao ponto.
Um index no banco de dados permite que o mecanismo de busca localize linhas com mais eficiência. Com um índice, o banco de dados não precisa escanear a tabela inteira.
- Sem um índice, encontrar um tópico significa escanear todas as páginas.
- Com um índice, você pode pular diretamente para a página correta.
Tipos de Índices:
- Single-column Index: Um índice em uma única coluna.
1
CREATE INDEX idx_goal_name ON goals(goal_name);
- Composite Index: Um índice em múltiplas colunas.
1
CREATE INDEX idx_name_type ON goals(goal_name, goal_type);
- Full-Text Index: Usado para buscas em texto, otimizando pesquisas em campos textuais grandes.
1
CREATE FULLTEXT INDEX idx_text ON articles(content);
- Unique Index: Garante que todos os valores nas colunas indexadas sejam únicos.
1
CREATE UNIQUE INDEX idx_unique_email ON users(email);
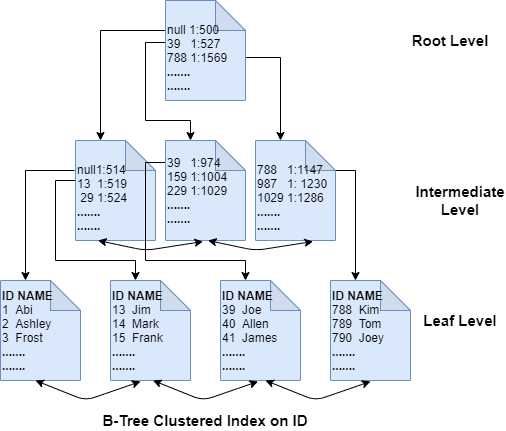
Clustered Index vs. Non-Clustered Index
Um clustered index determina a ordem física dos dados em uma tabela. Cada tabela pode ter apenas um clustered index, e ele é criado automaticamente quando uma PRIMARY KEY é definida.
1
2
3
4
5
CREATE TABLE goals (
id INT PRIMARY KEY, -- Por padrão, isso cria um clustered index
name NVARCHAR(100),
status INT
);
Um non-clustered index é uma estrutura separada que mantém um ponteiro para os dados reais na tabela.
1
CREATE NONCLUSTERED INDEX idx_goals ON goals(name);
- Os dados permanecem ordenados fisicamente pelo
id(clustered index). - O non-clustered index em
namecria uma estrutura separada com ponteiros para as linhas reais na tabela.
O mecanismo do banco de dados decide qual índice usar com base em cálculos de desempenho.
Se quiser saber mais e como aplicar, confira este post aqui!
Partitioning
Aqui está outra estratégia que pode melhorar o desempenho do seu banco de dados.
Partitioning é uma técnica que divide um banco de dados grande em pedaços menores, com base em um valor de intervalo. Imagine que você corta seu banco de dados em pequenas partes e define quais informações vão em cada uma delas.
Várias estratégias podem ser aplicadas aqui, como:
- Range Partitioning: Os dados são particionados com base em intervalos de valores, sendo mais eficiente e fácil de gerenciar.
- Exemplo: Uma tabela de transações é particionada por
transaction_date.
- Exemplo: Uma tabela de transações é particionada por
- Hash Partitioning: Os dados são particionados usando uma função de hash ou uma chave, como IDs.
- Exemplo: Uma tabela de transações é particionada por
transaction_idou um algoritmo de hash.
- Exemplo: Uma tabela de transações é particionada por
- List Partitioning: Os dados são particionados com base em categorias. Fácil de gerenciar, mas não recomendado para tabelas muito grandes.
- Exemplo: Uma tabela de transações é particionada por
transaction_countryoutransaction_bank.
- Exemplo: Uma tabela de transações é particionada por
O partitioning pode ser implementado de duas formas:
- Horizontal Partitioning: Divide uma tabela em linhas com base nos valores das colunas.
- Vertical Partitioning: Divide uma tabela com base em colunas, permitindo mover dados menos frequentes para um armazenamento “frio”.
Se quiser saber mais e como aplicar, confira este post aqui!
Replication
Amo quando o nome já explica exatamente o que o padrão é.
Replication é o processo de copiar e replicar dados de um servidor de banco de dados para outro. Com a replicação, você pode lidar com fault tolerance, manter o sistema sempre ativo e melhorar o desempenho. Se um servidor cair, você tem outro.
Ao lidar com replicação, temos dois tipos principais:
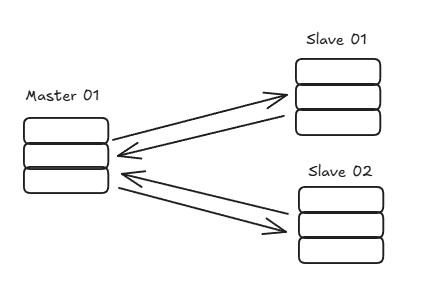
- Primary-Secondary (ou Master-Slave): O primary (master) lida com todas as escritas, e um ou mais secondaries (slaves) replicam os dados do primary e lidam com operações de leitura.
- Multi-Primary (ou Multi-Master): Vários servidores (masters) podem lidar com leituras e escritas, sincronizando e replicando entre si.
Claro, existem desafios, como manter a consistência entre réplicas, especialmente no segundo tipo. Algumas operações de escrita podem ficar mais lentas devido à sobrecarga da replicação.
Farei um post futuro apenas sobre esse tópico.
Sharding
Esta também é uma técnica de particionamento! Parece confuso, certo?
Vamos explicar a diferença entre sharding e partitioning:
- Partitioning significa dividir uma única tabela grande em partes menores chamadas partitions, ainda dentro da mesma instância do banco de dados.
- Sharding é uma forma de horizontal partitioning. Os dados são distribuídos em múltiplos bancos de dados independentes (shards).
O partitioning ocorre no nível da tabela, dentro da mesma instância. O sharding ocorre no nível do banco de dados, distribuindo os dados entre diferentes instâncias.
Como o Sharding funciona:
- Cada shard contém um subconjunto dos dados, dividido com base em uma shard_key.
- A aplicação determina qual shard consultar com base nessa mesma shard_key.
- Os shards podem ser distribuídos em diferentes servidores ou localizações.
Algumas estratégias para sharding:
- Range Sharding: Similar ao range partitioning, os dados são divididos em intervalos.
- Exemplo: Shard 1 → user_id 1-1000, Shard 2 → 1001-2000.
- Hash Sharding: Uma função de hash determina onde os dados serão distribuídos.
- Exemplo:
shard_id = hash(transaction_id) % total_shards. - Se
hash(1001) % 3 = 2, o usuário 1001 vai para o Shard 2.
- Exemplo:
- Geographical Sharding: Os dados são distribuídos por localização.
- Exemplo: Shard 1 → Usuários do Brasil, Shard 2 → Usuários da Argentina.
- Directory Sharding: Uma tabela armazena o mapeamento da shard_key para o shard correto.
- Exemplo:
SELECT shard_id FROM shard_mapping WHERE transaction_id = 1001;.
- Exemplo:
Consistent Hashing
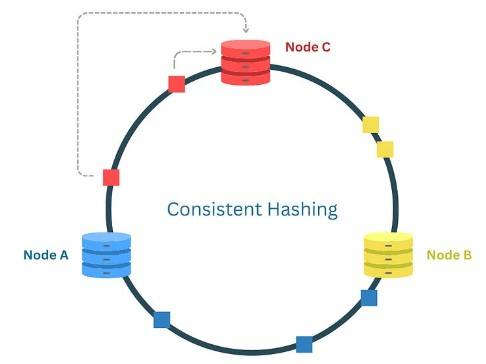
É uma técnica para distribuir dados entre múltiplos nodes (servers). Sua principal vantagem é que, quando nodes são adicionados ou removidos, apenas uma quantidade mínima de dados precisa ser redistribuída.
O consistent hashing funciona com um hash ring, um espaço circular. A função de hash mapeia os nodes e as chaves dentro desse anel.
- Exemplo:
- Nodes
A,B,Cestão nas posições 10, 30, 50 do anel. - Uma chave com hash 25 vai para o Node B (30).
- Uma chave com hash 45 vai para o Node C (50).
- Nodes
- Se um node é adicionado ou removido, apenas as chaves próximas se movem:
- Se o Node B (30) for removido, suas chaves vão para o próximo node (C).
- Se o Node D (40) for adicionado, ele só recebe algumas chaves do Node C (50).
ACID
As propriedades ACID garantem a integridade das transações em bancos de dados. São especialmente críticas em bancos relacionais (SQL).
- Atomicity (A) – “Tudo ou Nada”: Uma transação deve ser totalmente concluída ou totalmente revertida se qualquer parte falhar.
- Exemplo: Transferir R$100 de Ezio → Altair.
- Se o dinheiro for debitado de Ezio mas não creditado em Altair, a transação falha e é revertida.
- Se o sistema travar após a etapa (1) mas antes da (2), a transação é desfeita, garantindo que Ezio não perca dinheiro sem Altair receber.
- Exemplo: Transferir R$100 de Ezio → Altair.
- Consistency (C) – “Apenas Estado Válido”: Uma transação deve levar o banco de dados de um estado válido para outro, seguindo todas as regras.
- Exemplo: Um banco garante que a soma total das contas permaneça inalterada durante uma transferência.
- Se um erro fizer R$100 serem debitados de Ezio sem serem creditados em Altair, a transação é rejeitada.
- Exemplo: Um banco garante que a soma total das contas permaneça inalterada durante uma transferência.
- Isolation (I) – “Sem Leituras Sujas”: Transações não devem interferir umas nas outras. O resultado final deve ser o mesmo que se fossem executadas sequencialmente.
- Exemplo: Altair verifica seu saldo enquanto Ezio está transferindo dinheiro para ele.
- Sem isolamento, Altair poderia ver uma transação incompleta (Ezio debitado, mas Altair ainda não creditado).
- Exemplo: Altair verifica seu saldo enquanto Ezio está transferindo dinheiro para ele.
- Durability (D) – “Nunca Perdido”: Uma vez confirmada, uma transação deve ser armazenada permanentemente, mesmo em caso de falhas.
- Exemplo: Você reserva uma passagem de avião e recebe um e-mail de confirmação.
- Mesmo que o servidor trave logo depois, sua reserva permanece no banco de dados e estará disponível quando o sistema voltar.
- Exemplo: Você reserva uma passagem de avião e recebe um e-mail de confirmação.
CAP Theorem
O CAP Theorem é simples de entender e complexo ao mesmo tempo.
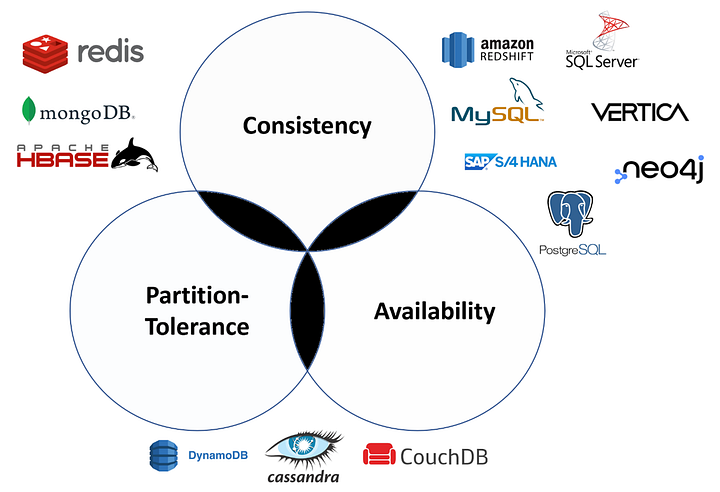
Esse teorema afirma que um sistema distribuído pode garantir no máximo duas das três propriedades:
- Consistency (C) → Toda leitura recebe a escrita mais recente ou um erro.
- Availability (A) → Toda requisição recebe uma resposta (possivelmente desatualizada).
- Partition Tolerance (P) → O sistema continua funcionando mesmo com falhas de rede.
Um sistema distribuído deve tolerar partições de rede (P), então ele só pode escolher entre Consistência (C) e Disponibilidade (A).
Imagine um banco de dados distribuído em vários servidores. Se ocorrer uma falha de rede entre dois data centers:
- Se o sistema priorizar Consistência (C), algumas requisições falharão para garantir os dados mais recentes.
- Se o sistema priorizar Disponibilidade (A), retornará dados desatualizados para garantir respostas.
Você precisa escolher entre Consistência ou Disponibilidade ao usar SQL Server:
–
Obrigado por ler até aqui!